[论文笔记]多模态瑞士军刀模型 4M-21
💡 4M-21 Paper (2024) | 4M Paper (2023) |Demo | Code |Website
Author: EPFL(洛桑联邦理工学院)& Apple @ Jun 2024
TL;DR
4M-21 是苹果开源的一个多模态、多任务的视觉模型,可以采用任意模态组合作为输入,预测其他模态的输出。模型支持 21 种模态,包括 RGB 图像、几何信息、语义信息、边缘特征、特征图、元数据和文本等。该模型在大规模多模态数据集和文本语料上进行联合训练。
| 研究亮点 | 用单个视觉模型任意转化多个模态,完成数十种不同的任务,为多模态交互带来新的可能性。 |
|---|---|
| 研究动机 | 提高效率:不用为每个任务分别训练模型;增强模型多任务处理能力;Any-to-any learning:环境感知和多感官融合 |
| 研究难点 | 多模态融合,任务选取,多任务导致性能下降 |
| 研究方向的启发 | 多模态实时预测,端侧模型能力提升,从模态角度辅助交互场景分类和建模 |

论文摘要
当前的多模态和多任务基础模型,如 4M 或 UnifiedIO,显示出有希望的结果。然而,它们接受不同输入和执行不同任务的开箱即用能力,受到它们接受训练的模态和任务的数量(通常很少)的限制。在这项工作中,我们开发了一个任何到任何的单个模型,在数十种高度多样化的模态上进行联合训练,并在大规模多模态数据集和文本语料库上进行协同训练。这包括对图像和文本以及几个语义和几何模态、最近最先进的模型(如 DINOv2 和 ImageBind)的功能图、专家模型(如 SAM 和 4DHumans)的伪标签以及一系列新的模态进行训练,这些新的模态允许与模型交互的新方式来引导生成,例如图像元数据或调色板。这一过程中的一个关键步骤是在各种模态之间进行离散标记化,无论它们是否像图像、神经网络特征图、向量、结构化数据(如实例分割或人体姿势)、可以表示为文本的数据等。
通过这种方式,我们展示了训练一个模型来解决至少比现有模型多出 3 倍的任务/模态的可能性,并且不损失性能。此外,这使得我们可以实现更精细、可控的多模式生成能力,并能够研究针对多样化数据和目标进行训练的模型如何融入到一个统一的模型中。我们在三个参数和不同的数据集上对训练进行了扩展。多模式模型和训练代码可以在 https://4m.epfl.ch/ 上获得。
4M-21 的多模态能力
视觉模型需要处理各种感觉输入,如图像、三维和文本,并完成多样的任务。4M-21 在 4M(massively multimodal masked modeling 大规模多模态掩码模型) 基础上扩展了多模态能力:
- 可控多模态生成:从给定的输入模态生成所有模态,并且文本理解能力也得到增强,可以实现更具几何形状和语义合理性的生成。
- 多模态检索:模型学习了将不同模态映射到语义空间的能力,能预测全局嵌入,而不是直接使用这些模型的原始特征。这解锁了 DINOv2 和 ImageBind 模型无法实现的检索功能,例如以任何模态来检索 RGB 图像或任何其他模态。此外,可以组合多个模态以预测全局嵌入,从而更好地控制检索。
- 细粒度多模态编辑:可以执行各种多模态编辑任务,例如进行语义编辑或基于几何条件的填充。某些模态(如语义分割或深度图)可以作为生成过程中的中间步骤,为后续模态的生成奠定基础。
优势:
- 跨模态学习:可以同时处理多种类型的数据,能够更好地捕捉到不同类型数据之间的关系。
- 多模态生成:在生成高质量图像时更加灵活和准确。
- 强大的泛化能力:模型经过大规模的预训练,泛化能力很强,在各种视觉任务中都表现良好。
训练方法
先将所有模态通过特定模态的分词器转换为离散标记序列。在训练过程中,从所有模态中随机选择一部分 token 作为输入而另一部分作为目标,训练模型从一个子集预测另一个子集。
1. Modalities
模型支持 8 类共 21 种模态:RGB、几何、语义、边缘、特征图、全局特征、文本和元数据
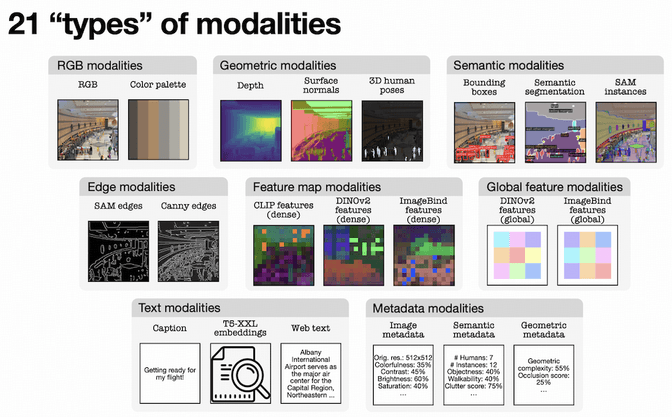
- RGB:包含分词版本和像素版本的 RGB 图像。使用 PyPalette 从不同数量的颜色中提取了色板。
- Geometric:包含表面法线、深度和三维人体姿势与形状,提供了场景几何的重要信息。前两项使用了全数据模型进行伪标记。对于三维人体姿势和形状,则利用了最新的 4D-Humans 模型。
- Semantic:包含语义分割和边界框来捕获场景语义,并使用模型进行伪标记。此外还从 SAM 中提取了伪标签作为 SAM 实例。
- Edges:边缘承载有关场景布局和语义的重要信息。Canny 边缘由 OpenCV 从 RGB 图像中提取。由于 Canny 可能包含低级信息(例如阴影边缘),因此还加入了从 SAM 实例中提取的边缘以获得更具语义的边界映射。
- Feature map&Global feature:从 CLIP、DINOv2 和 ImageBind 中提取 embeddings,因为它们展示了强大的迁移学习和检索能力,能够蒸馏出场景的有用语义表示。
- Metadata:
- 语义元数据:从边界框、姿势和分割映射中提取出人群密集度分数,SAM clutter 分数,COCO clutter 分数,COCO 实例多样性,对象分数,步行指数,语义多样性,标题长度等。
- 几何元数据:几何复杂度,遮蔽分数。
- 图像处理元数据:图像高度和宽度,亮度,对比度,饱和度,色彩丰富度,图像熵。
- Text:Caption(CC12M 和 COYO700M),Web Text(C4),embeddings(T5-XXL)
2. Dataset
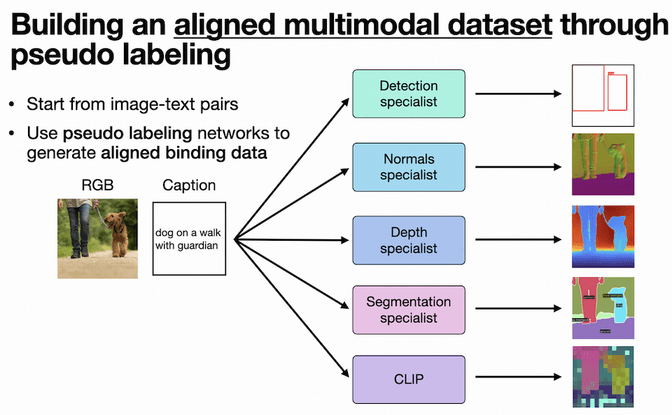
训练新的模型首先要解决数据集的问题。现有多模态数据集一般都数据量较小且不够多样,研究者以图像和文本对作为基础,用伪标签网络来创建一个多模态对齐的大规模预训练数据集。
3. Tokenization
这是模型训练的关键步骤:不同模态,统一编码。
将各种模态(特征图、实例分割或人体姿态、文本等)转换为序列或离散 tokens,统一为一种通用的表示,并在 transformer 架构基础上训练。这样一来,模态之间的映射关系,就转换成了从一组 token 序列预测另一组序列。
https://storage.googleapis.com/four_m_site/videos/4M_method_figure.mp4#t=25.9
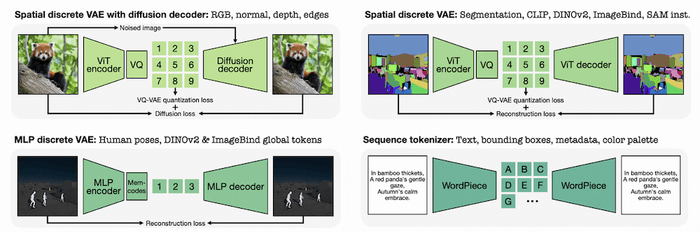
使用的 tokenizer 包括三类:
- VQ-VAE:
- 使用扩散模型作为解码器来训练 VQ-VAE:针对细节丰富的图像类模态,如 RGB、法线、深度、边缘
- ViT 解码器:其他图像类模态,如语意或实例分割、特征图
- MLP:针对 3D 人体姿态或图像嵌入类的模态,得到一维序列
- WordPiece:针对文本表示的模态,如标题或元数据
tokenization 的作用:
- 所有任务都可以使用交叉熵损失(cross-entropy loss)作为 token 的分类问题进行建模。这提高了训练稳定性,可共享参数。
- 模型可以迭代地预测 token,使生成性任务更易于处理,要么自回归,要么通过渐进式 unmasking。
- 减少计算复杂度,例如将密集模态压缩为稀疏标记序列来压缩,降低了内存和计算需求。
4. 训练
训练目标是得到多模态掩码预测模型。模型使用 Transformer 结构,通过输入模态的 token 序列,预测 DINOv2 和 ImageBind 的全局嵌入。这意味着模型学习了将不同模态映射到语义空间的能力。
编码
编码器是一个标准的 Transformer 编码器,但具有针对每种模态学习输入嵌入层的功能,以将标记索引映射到向量。~~对于特定模态中的每个标记,添加一个可学习的模式嵌入,并为序列或稠密模式(2D)添加 sin-cos 位置嵌入。~~为了便于迁移学习,编码器额外设计了使用可学习的分块线性投影接受 RGB 像素的能力,使其可以用作视觉 Transformer 的骨干,从而可以作为迁移学习中的 ViT 背景知识。
掩码策略
从所有模态中采样并编码一小部分可见标记,使用了多模态随机和跨度掩码策略来遮挡输入和目标标记,并训练模型执行跨模态预测编码。

训练过程
训练分为两个阶段:在更大的图像数据集上进行 4M 预训练,然后在一个包含更多模态的小型数据集上进行微调。
多模态链式生成
经过训练的 4M 模型可以用于从其他模态的任何组合生成任何模态,并且能够从部分输入执行预测。当从一个模态预测多个模态时,可以逐个预测,始终将完全生成的模态循环回输入,并根据它们来调节后续模态的生成。
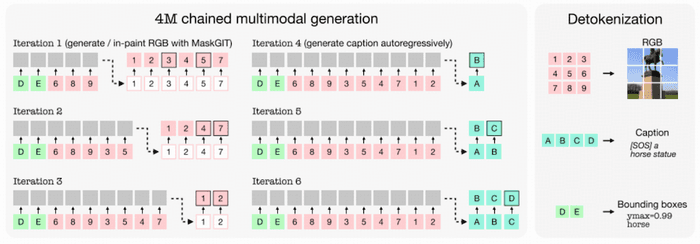
链式多模态生成。使用 MaskGIT 解码方案从部分 RGB 输入以及边框中生成一张完整的 RGB 图像,然后对标题进行自回归生成。通过串联可以预测多个模态。这与独立地从原始条件中为每个模态生成不同,并且每个生成输出都与输入一致。可以使用解码器将生成的标记转换回图像、文本和其他模态。