软件 2.0 和 GenAI 应用技术栈
AI that can create software would be the perfect lever on software itself, which in turn is the perfect lever upon the world. 能够创建软件的人工智能将是软件本身的完美杠杆,而软件本身又是世界的完美杠杆。
The Compound Lever: AI for Software Engineering | Sequoia Capital
软件 2.0
软件 2.0 是一种新的软件开发范式,主要利用机器学习算法和神经网络来构建自主系统。
这个概念最早由 Andrej Karpathy 在 2017 年提出 。Andrej 师从 Geoffrey Hinton,在斯坦福李飞飞团队获得博士学位,主要研究 NLP 和计算机视觉,然后作为创始团队成员加入了 OpenAI,在 2017 年加入 Tesla 负责自动驾驶研发。
大脑的工作方式肯定不是靠某人用规则来编程。 ——Geoffrey Hinton
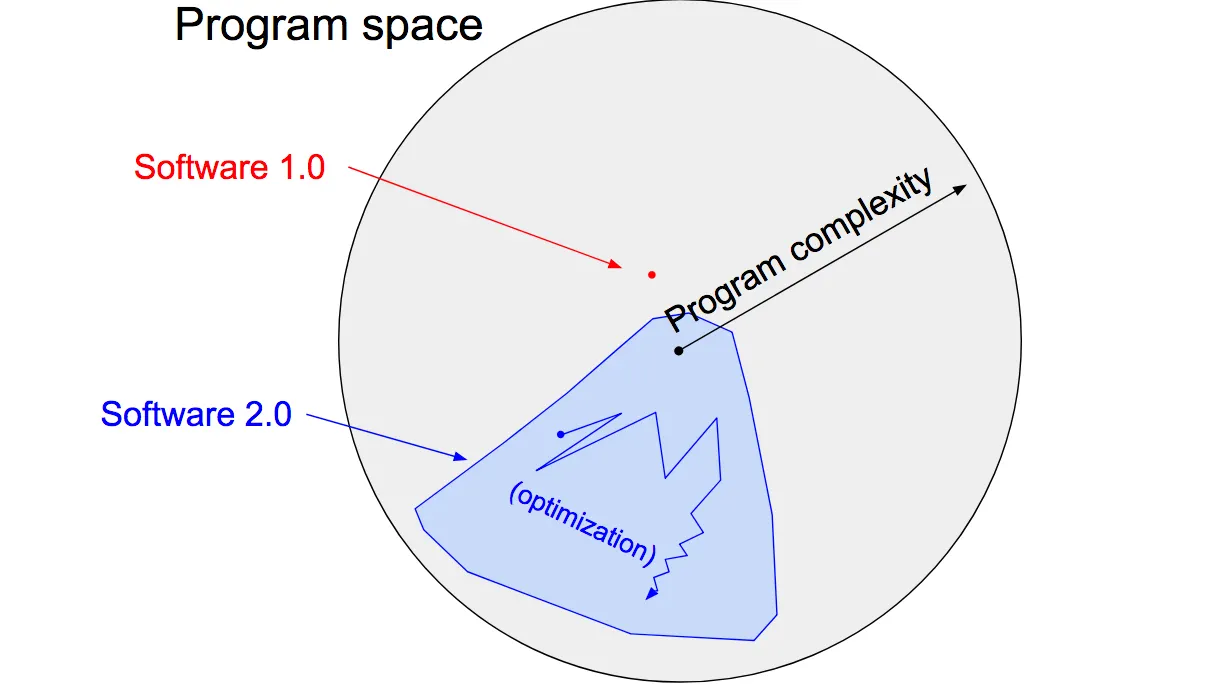
软件 2.0 代表了软件开发方式的根本转变,不再需要人为编写程序的具体指令,而是通过定义期望行为和搭建神经网络架构,让计算资源自行创建符合要求的程序。与传统的软件 1.0 相比,软件 2.0 具有计算均匀、易于嵌入硬件、运行时间和内存使用稳定、高度可移植、灵活性强等优势。
| 软件 1.0 | 软件 2.0 | |
|---|---|---|
| 开发模式 | 由人类手动编写具体代码。 | 人类教 AI 写软件,定义期望行为、搭建神经网络架构,并使用可支配的计算资源来搜索程序空间以寻找有效的程序。 |
| 技术架构 | 代码用 Python、C++等语言编写的计算机显式指令组成。 | 代码用更抽象、对人类不友好的语言编写,例如神经网络的权重。 |
| 特点与优势 | 规则驱动,程序员通过编写明确的指令来控制程序的行为。代码逻辑直观可理解。 | 数据驱动,通过优化评价标准来编写代码,优化可以找到比人类能写的更好的代码。灵活性强、易于嵌入硬件。 |
| 应用场景 | 适用于需要明确指令和规则的场景。 | 适用于可以重复评估、成本低廉且算法本身难以明确设计的领域,例如图像、视频、声音、语音相关的内容。 |
| 编译过程 | 将人工设计的源码(如.cpp 文件)编译为可以有效工作的二进制文件。 | 源码通常由两部分组成:1)定义了目标行为的数据集;2)给定代码大致结构,但是需要填充细节的神经网络结构。训练神经网络的过程,就是将数据集编译成二进制文件的过程,得到最终的神经网络。 |
| 安全性 | 相对容易防御攻击 | 易受对抗样本(adversarial examples)攻击 |
典型案例 1:Midjourney
Midjourney 作为人工智能图像生成领域的佼佼者,是软件 2.0 范式的典型代表。它充分体现了软件 2.0 的核心特征:基于神经网络和机器学习模型,通过高度抽象的方式实现复杂功能。用户只需输入文本提示词,Midjourney 就能生成令人惊叹的图像。Midjourney 的性能主要依赖于其训练数据,而不是传统的手写代码。通过不断学习和更新,Midjourney 持续改进其性能,体现了软件 2.0 的自动整合特性。
典型案例 2:Tesla FSD
特斯拉的全自动驾驶(Full Self-Driving, FSD)系统同样可以被视为软件 2.0 范式的典型代表。FSD 依赖于神经网络和机器学习模型,而非传统的手写代码。FSD 版本 12.1.2 已经完全转向基于神经网络的端到端系统,通过大量的视频数据进行训练和优化。FSD 的开发和改进主要依赖于大量的真实世界数据,通过不断的学习和更新来提升其决策能力。FSD 通过持续的 OTA(Over-the-Air)软件更新来提升性能和增加新功能。这种高度依赖数据和自动优化,也是软件 2.0 的典型特性。
尽管 FSD 目前仍需驾驶员监督,但其通过神经网络实现的复杂功能和持续优化的能力,展示了巨大潜力和优势。
端到端要素
随着 AI 作为一种新的杠杆出现,我们正在从“学习代码”向“用自然语言指导机器”过渡。未来的 AI 应用,这三个要素会越来越重要:
- 用户目标:终点决定起点,端到端应用会越来越主流,而准确定义用户目标是第一步
- 数据集:能反映目标行为的高质量数据集是成功的关键
- 程序架构:架构决定了准确性、效率、性能,开发过程从代码迭代变成架构调优实验
Modern AI Stack
虽然软件 2.0 时代(另外一种说法是 3.0 )还没完全到来,什么是 AI Native App 也众说纷纭,但是随着 LLM 的普及、成本快速下降,软件开发的整个 landscape 已经发生了很多变化。下面对生成式 AI 技术栈做一个简单的整理。
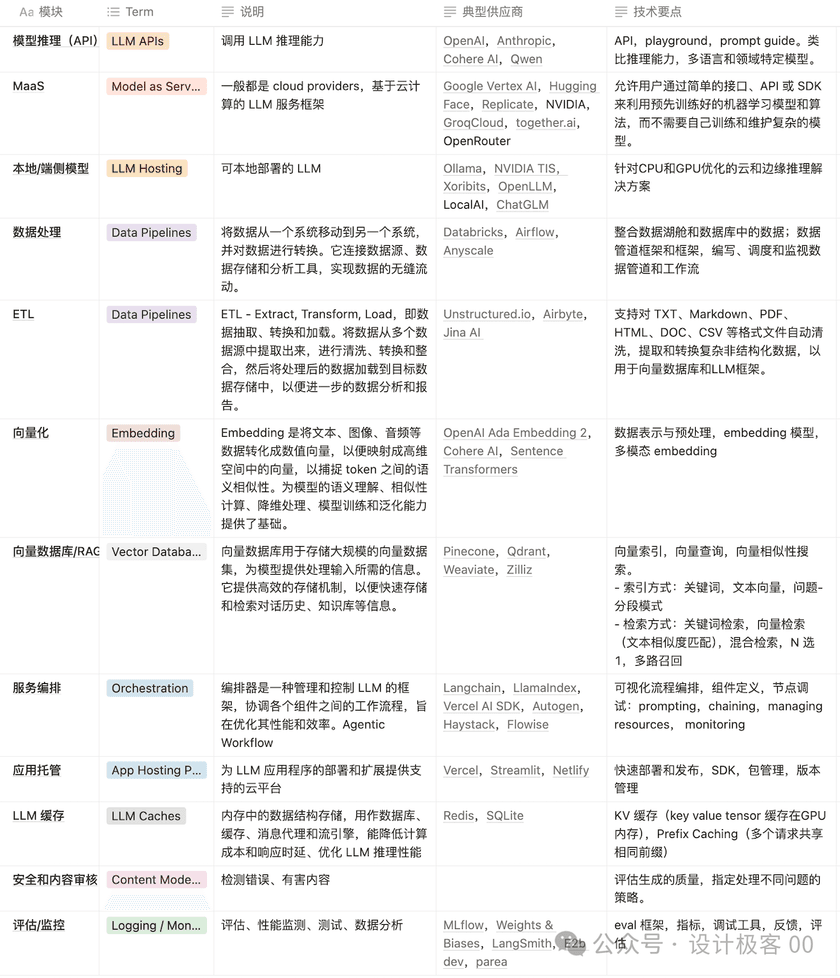
- 模型推理(API):调用 LLM 推理能力
- MaaS:一般都是 cloud providers,基于云计算的 LLM 服务框架
- 本地/端侧模型:可本地部署的 LLM
- 数据处理:将数据从一个系统移动到另一个系统,并对数据进行转换。它连接数据源、数据存储和分析工具,实现数据的无缝流动。
- ETL:Extract, Transform, Load,即数据抽取、转换和加载。将数据从多个数据源中提取出来,进行清洗、转换和整合,然后将处理后的数据加载到目标数据存储中,以便进一步的数据分析和报告。
- 向量化:Embedding 是将文本、图像、音频等数据转化成数值向量,以便映射成高维空间中的向量,以捕捉 token 之间的语义相似性。为模型的语义理解、相似性计算、降维处理、模型训练和泛化能力提供了基础。
- 向量数据库/RAG:向量数据库用于存储大规模的向量数据集,为模型提供处理输入所需的信息。它提供高效的存储机制,以便快速存储和检索对话历史、知识库等信息。
- 服务编排:编排器是一种管理和控制 LLM 的框架,协调各个组件之间的工作流程,旨在优化其性能和效率。Agentic Workflow
- 应用托管:为 LLM 应用程序的部署和扩展提供支持的云平台
- LLM 缓存:内存中的数据结构存储,用作数据库、缓存、消息代理和流引擎,能降低计算成本和响应时延、优化 LLM 推理性能
- 安全和内容审核:检测错误、有害内容
- 评估/监控:评估、性能监测、测试、数据分析
构建一个完整的 AI 应用,会涉及到很多组件和流程,可以按照数据的流转把它们组织起来形成一个较为全局的概念(via ):
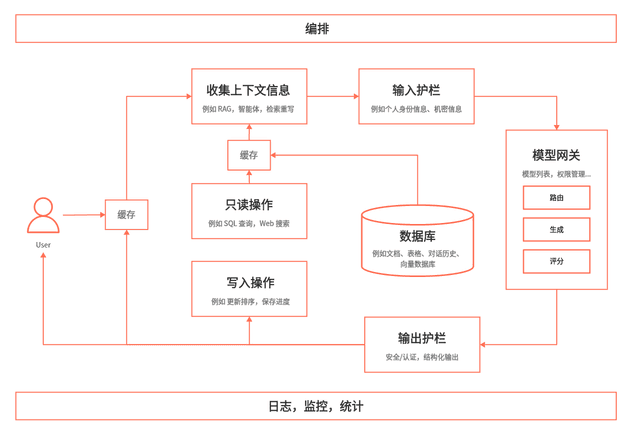
红杉曾经整理了一个 AI infra 的堆栈图,可以帮助我们以更为全局的视角理解不同的 AI 技术栈在生态中所扮演的角色:
Generative AI’s Act Two | Sequoia Capital 2023.9.20
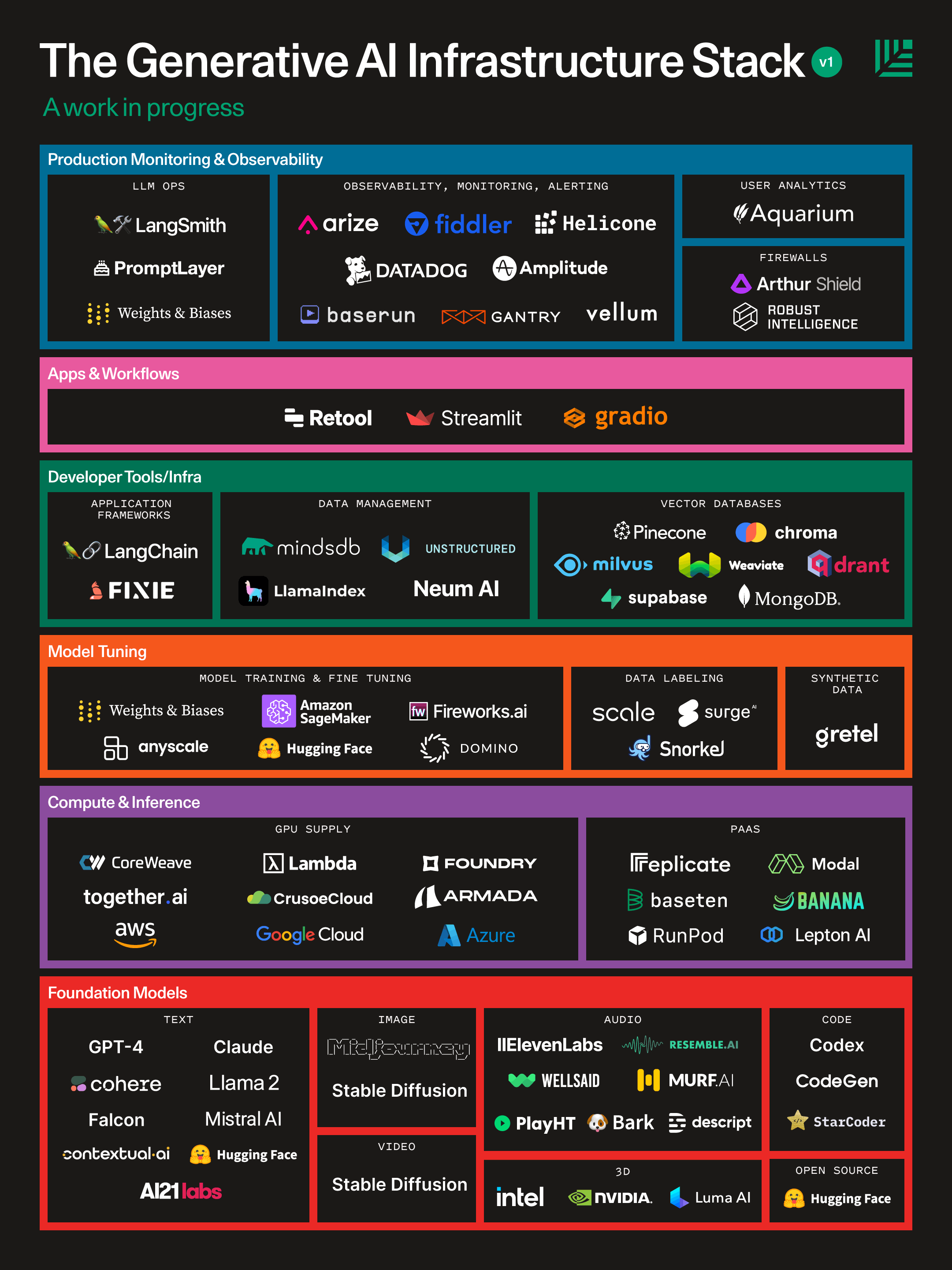
这张图发布已经过去快一年,整个生态变得更加丰富。AI 技术栈仍然在快速演进中,让我们持续关注。