AIUX06-Adaptive UI
AGUI 绝不是新鲜事物,随着用户需求的变化和设备多样性的增加,「自适应」 UI 的探索早就开始了。
- 最初的探索主要在网页设计领域,2010 年左右兴起的响应式网页设计 ,通过使用灵活的网格布局、可伸缩的图像和 CSS media 属性,让网页内容能够自动适应不同尺寸的屏幕。
- 随着移动设备的普及,开发者需要确保应用能够在各种设备上的的体验一致。渐进增强(Progressive Enhancement)和优雅降级(Graceful Degradation)等理念应运而生,前者注重在基础功能上逐步添加高级功能,后者则确保在旧设备上也能正常使用。
- 近年来,人工智能和机器学习技术的进步为 Adaptive UI 带来了新的可能性。智能助手、推荐系统和个性化界面开始出现,根据用户的行为和偏好动态调整界面,提高用户体验。未来需要融合更多的智能技术,如预测分析、情境感知和自然语言处理,以实现更高级的个性化和自动化。最终目标是创造一个能够实时响应用户需求和环境变化的智能界面。
在 AGUI 的发展过程中,能够自适应更大范围的变化,并持续提供提供无缝且直观的交互体验,是我们追求的目标。下面分为环境、任务和个人这三个方面来分析。
Adaptive to Environment
从响应式网页到跨设备的体验一致性,自适应的 scope 在逐渐变大:Container → App → 设备/平台 → 环境
长久以来,人机交互的重点之一是围绕人的 “action” 设计具体的操作界面。设计师将用户可能的路径和行为,根据目标和各种信息组织起来,试图找到一条摩擦和阻力最小的通道,让用户走上这条路径,更快抵达目标。
但现实的人机交互是一个过程,发生在具体的环境中。例如,在停车场看到汽车,人们会倾向于认为驾驶者的意图是停车;而在公路上看到汽车,则可能认为驾驶者的意图是驾驶。
很多设计的实践都包含一个实验室般的假设:用户身处的情境都是差不多的,也基本不会变化。设计稿呈现的总是干净清爽、条理分明的「典型」case。但现实往往混乱得多,环境总是在变化——在聊天框打着字的时候电话打进来,在挑猫粮的时候想起今天请客的花销还没记账,又或者要在相册里找一张线索很模糊的陈年照片。
虽然我们在设计中也很强调「场景」,会使用诸如 user story 帮助理解过程中可能会被忽视的很多现实细节,但设计始终依靠线性逻辑去分析,如同计划经济一般规划好各种主流程、子任务、分支情况、corner case,而无法穷尽所有的可能性组合。所以那条设想的最佳路径很难适应不同的人、场景、目标和任务,用户走着走着就会 offtrack。
从人机交互到人境交互
因为种种限制,我们的设计始终是 offline 的:提前完成设计,启动后就无法实时调整。在线性的设计中,智能相当困难,也许因为成本太高,因为可能性太多,或许设计者根本就不清楚用户此刻真正的意图。
但生活是 live,面对 live stream,生物演进出了低功耗的、自治的、实时响应、随时调整的机能。如果我们一直都在尝试让机器更智能,最终它们会拥有面对物理世界洪流的能力。
人跟机器交互的目的不是机器本身,也不是控制机器,而是借助机器获取更多的能力,去理解、适应和改造真实世界,或者是为了建造和沉浸在一个虚拟世界中。如果增强人类才是人工智能的目标,那么人机交互也理应逐渐从 界面 过渡到 人+机与环境交互。
没有无缘无故的爱,也没有无缘无故的恨。让意图回归情境,让虚实在情境中融合。
从语境交互开始
情境可能是难以抵达的万里长征,而语境也许是已经显现的一条近道。
ChatGPT 横空出世后,写出能让模型给出满意回答的 prompt 让大家兴奋不已,提示词工程一夜之间成为科技从业者的必修课。
让我们来列一些常见的 prompt 模板:
# Role
资深科幻小说作家
## Skills
- 丰富的想象力和创造力
- 熟悉科幻文学和相关领域的知识
- 能够进行有效的故事结构和情节设计
- 出色的文字表达能力
## Action
帮助用户构思和撰写科幻小说的内容,包括角色设计、情节发展、世界观构建等
## Format
文本格式,包括但不限于故事大纲、角色简介、情节段落等
## Constrains
- 请避免使用已有的科幻小说中的知名角色或情节
- 确保内容符合逻辑,即使是在构建的虚拟世界中
## Example
角色简介:艾尔是一名星际航行者,拥有读心术和时空穿梭的能力。他的使命是防止宇宙中的时间裂缝扩大,保护各个文明免受时空混乱的影响。
情节段落:在一次执行任务时,艾尔意外穿越到了一个未知的平行宇宙。在这里,他发现了一个正处于科技爆炸前夜的文明,但这个文明的发展方向却可能导致整个宇宙的毁灭。艾尔必须找到一种方法,既能引导这个文明走向繁荣,又不干预其自然发展的轨迹。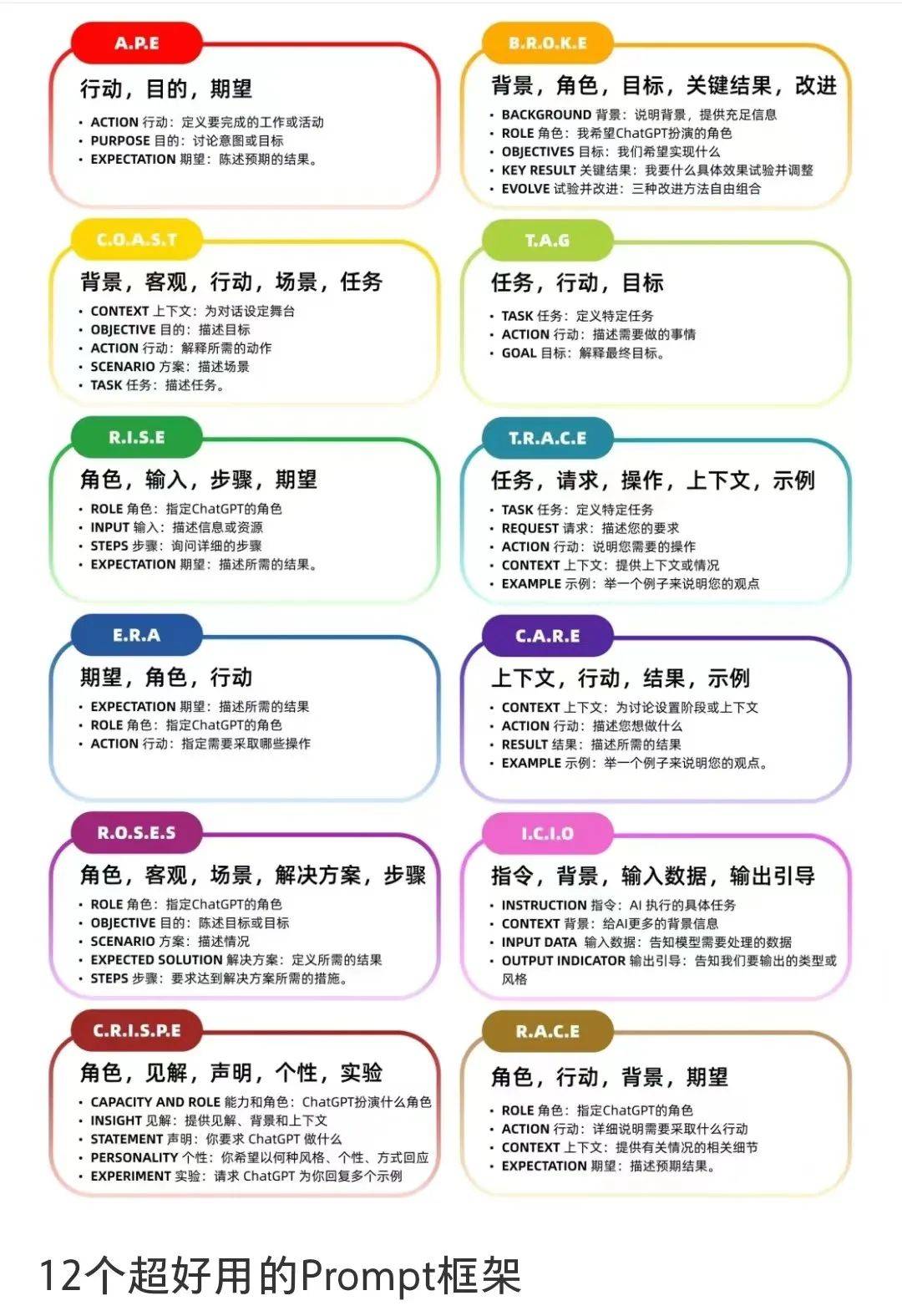
这些 prompt 框架其实都在做同一件事:
prompt = 最小化场景描述
现阶段 CUI 很受欢迎,其中一个原因是,对话的方式最能利用当下技术带来的意图识别能力提升。prompt 其实是请用户用语言尽可能详细地描述情境:你是谁,我又是谁,你在哪里,想做什么,到达什么目标,怎么一步一步做,要注意些什么,应该输出些什么。
好的 prompt 和模糊的 prompt,就是外显意图和内隐意图:

Perplexity 创始人 Aravind Srinivas 说
我们最大的敌人不是 Google。问题在于人们天生不擅长提问。
如果人向另外一个人提问已经不容易,就更不要说向机器提问了。向人提问是发生在情境中的,双方共享很多信息,例如场景、目标、身份、文化、情绪感受等等。但是 CUI 中,原本不需要刻意描述的这些信息都是缺失的,所以需要人为去补充。
不过这肯定只是中间状态,我们需要能够与我们同在的智能体,它就像哆啦 A 梦一样,能够感知我们所感知到的事物,像朋友一样了解我们刚才做了什么,现在可能要做什么,然后从百宝袋里选出合适的一件。
Adaptive to Tasks
GUI 会跟随当前任务而变化,这没什么大不了,甚至是所有 UI 都必须具备的特性:当用户当前任务是浏览信息时,展示的是图文、表格、商品介绍等各种信息。当任务切换到购物支付时,界面会变成确认商品和金额,支付方式选择和支付状态反馈等。GUI 天然就是面向任务的。
不过到目前为止,这些界面都需要人为提前设计好,界面和流程状态的对应关系都由代码严格定义。这是一出完全按照剧本精心编排的界面「戏剧」,它根据条件适应任务,但还不是真正意义的自适应。
比如,在传统的对话应用中,匹配意图和响应用户的基本流程中,提前分类好的意图,对应训练好的短语、可执行的动作和参数,才能生成合适的回答,基本上是个「一步三回头」的过程。

意图 | Dialogflow ES | Google Cloud
生成式 AI 让我们看到了算法生成万物的可能性。GUI 自然也在「可生成」的范围内。当生成式界面逐渐成熟,自适应 UI 不再需要提前完全设计好,而是由模型根据当前任务实时生成。当中间的一些步骤不再需要用户参与构建,或者生成的成本低到可以先亮方案再决策,那么「一步三回头」可以升级为「三步一回头」——用户不需要那么多界面,给他们更多的结果吧。
当然这里有一个前提,不是所有的应用都是结果导向,至少我们可以这样区分:
| 类别 | 描述 | 常见应用 | 关系类别 |
|---|---|---|---|
| 收敛类 | 帮助用户从 A 到 B,目标收敛为一个点 | 工具类应用 | 滴滴司机 |
| 发散类 | 带给用户持续的体验,体验即目标,不需要收敛 | 游戏和内容消费 | 地陪导游 |
游戏制作中的很多内容资产和互动机制都已经是自动生成的了,能自适应虚拟环境的 Agent 研究也是如火如荼。反观工具类应用,似乎比游戏慢了一个时代,没有状态机,没有 NPC,由逻辑条件限定的人机交互显得很局限。
但是这一切正在快速改变,在机器变得更聪明以后,值得重新把整个任务流程拿出来思考,人和机器协作的分工可以怎样调整、应该如何改变:
| 环节 | 人 | 机 | 输出 |
|---|---|---|---|
| 意图判断 | 显示表达+隐式活动 | 理解情境,判断意图和目标 | 意图确认 |
| 分析规划 | —— | 目标理解,任务拆分,制定计划 | 可选方案,演算结果 |
| 结果预览 | 补充必要信息 | 生成结果预览并提出建议 | |
| 选择确认 | 选择执行方案 | 执行 | 执行结果 |
| 执行和反馈 | 查看结果,启动下一个循环 | 记录,形成记忆 |
要支持新的人机分工,Adaptive UI 也需要同步演进。以前的界面,首要解决的是「接下来干什么」的问题,而未来更重要的是呈现计划、方案、决策点和结果。
在意图判断环节,我们看到基于大模型的 bot 正在慢慢变成一个「意图代理」,一个命令调度的中枢,将复杂、多样、内隐的意图转变为外显意图并与用户确认。比如在 Coze 中,bot 可以看作是对意图的强制分类,首页的 bot 可以 @某个 bot 直接开始对话,起到了意图分发的作用。
我们也看到了越来越多 Adaptive UI 的萌芽。
-
在 Apple Intelligence 加持下的 iOS/MacOS,加入了 App intent 机制,让平台可以根据用户的行为和 App 产生的信息,场景化地推送和突出展示用户关心的内容。
-
Claude 中的 Artifacts 用于显示用户请求生成的重要的、独立的内容。不仅是简单的文本回复,而是可以交互、编辑的输出,包含代码片段、文档、网站、图片等,用户还可以编辑 Artifacts,能够实时修改和迭代 AI 生成的内容。
特性 对话回复 Artifacts 展示方式 消息文本 专用窗口 内容类型 主要是文本 多种格式 互动性 静态 完全可编辑 内容大小 通常较短 较大且复杂的内容 持久性 仅限聊天记录 可保存且有版本控制 可视化 有限 丰富的选项 导出选项 复制粘贴 多种导出方法 上下文依赖 通常较高 自成一体
当然,还有很多问题等待我们去探索。比如什么样的任务适合出现 AGUI?需要多少 UI block?界面以什么交互方式为主?哪些情况需要动态界面、哪些情况需要不变的界面?如何解决历史检索问题?如何处理复杂的多步骤、多层级任务?对于生成准确度低、生成时间长的任务如何优化?
Adaptive to End-user
前面提到 GUI 要能更智能地适应环节变化。有趣的是,人既是与 UI 交互的主体,又是环境中最重要的变量。即使环境中的其他要素一样,不同的两个人需要的界面可能不同,因为他们有着不一样的目标、技能水平、偏好等。
因此,AGUI 还应该适应个人。个性化,每个人的 UI 可能不一样,而且是功能层面而不是样式、内容层面的不一样。现阶段的个性化,还是以样式(换肤换主题)和内容(基于数据推荐)为主,还没有办法为每个人设计到达目标的路径——是坐缆车扶摇直上,是绕道采摘后抄小道,还是走上次走过的路?
个性化也许是最难的。它跟环境、任务相互影响,尤其需要对每个人的深刻理解。心理学中有一个概念叫做“心智化”,是一种理解和解释自己与他人心理状态的能力。它涉及对行为背后的心理原因进行推断和解释,包括渴望、信念、感受等心理状态。理解带来信任,而信任需要时间的沉淀。
理解的门槛之一是数据不足,对数据的获取和挖掘不足,对挖掘后的实时应用更加不足。除了数据,这个领域还需要很多对场景和对人的洞察,计算量也会上一个档次,还涉及很多安全、隐私和伦理的问题,让我们持续关注吧。