[论文笔记] Titans: Google 新推的记忆架构
短期记忆(注意力机制)+长期记忆(神经记忆模块)
主要贡献:
- 提出了一个新的神经长期记忆模块,可以学习记住历史上下文并帮助注意力机制利用长期信息
- 设计了三种不同的架构变体来整合记忆模块
- 在多个任务上的实验表明该模型比传统 Transformer 模型更有效
- 可以扩展到超过 2M 的上下文窗口大小,同时保持较高的准确率
研究背景
参考神经心理学中记忆和学习的定义中感,大多数架构将记忆视为由输入引起的神经更新,将学习定义为在给定目标下获得有效和有用记忆的过程。
-
RNN 是具有向量值记忆模块 M 的模型,有两个主要步骤:给定在时间 t 的输入 x*t,模型使用函数 更新记忆,并使用函数 检索输入的记忆。
-
Transformers 是具有不断增长的记忆的架构。key-value 矩阵对充当模型的记忆,模型通过将 key 和 value 附加到内存(未压缩)来更新,以及 通过查找 query 向量和 key 向量的相似性来检索 query 向量的相应记忆,然后对输出的 value 向量进行加权。
需要新的记忆结构来回答 5 个问题
-
什么构成了记忆的良好结构?
-
什么是适当的内存更新机制?
-
什么是好的记忆检索过程?
-
如何设计一个包含不同互连内存模块的高效架构?
-
是否需要深度内存模块来有效地存储 / 记住很久以前的内容?
神经长期记忆模块
动态学习历史信息的抽象表示,通过元学习(惊讶程度)在测试时调整参数。
受人类长期记忆系统启发,设计一个能在测试时学习记忆的模块,克服现有模型缺乏长期记忆和有效记忆管理的问题。
类似于人类大脑的长期记忆:
- 重要的事件更容易被记住(惊讶度高 → 记忆更新幅度大)。
- 无关紧要的信息会被逐渐遗忘(遗忘系数 αt 控制旧记忆的衰减)。
- 近期的记忆对当前认知有更大影响(动量项 St 提供历史记忆平滑性)。
动态适应新数据:
- 记忆模块可以在测试时持续学习,避免过度依赖训练数据(即“过拟合训练集”)。
- 遇到新任务时,Titans 可以自动调整记忆,无需重新训练整个模型。记忆更新机制:Surprise-Driven
不符合预期(即令人惊讶)的事件更令人难忘。在模型中,通过输入的梯度(输入数据与过去数据的差异)来衡量惊讶程度,梯度越大表示输入与历史差异越大,从而触发记忆更新。
- k_t 和 v_t 是当前输入 x_t 投影到 Key-Value Pairs 的结果
- 模型模仿人类对 “令人惊讶” 事件的记忆方式,将更具差异性的数据作为记忆的重点,从而更有效地捕捉和存储重要信息。
记忆更新公式:
其中
- S_t 是动量元素,结合了过去惊讶(Past Surprise)和瞬时梯度(Momentary Surprise),类似于带动量项的梯度下降
- 是数据相关的 surprise 衰减( 的函数),控制惊讶如何随时间衰减
- 控制应以数据依赖性方式将多少瞬时惊讶纳入最终惊讶指标
- 是当前输入的惊讶度,即损失对记忆的梯度
记忆遗忘机制:Weight Decay
- 基于关联记忆的损失函数,通过衰减系数 动态控制记忆保留比例,防止信息过载。
- 若数据与过去高度相关,则保留更多历史记忆,即 ,几乎不遗忘,完整保留历史信息;
- 若数据变化较大,则适当遗忘旧记忆,即 ,完全清除历史记忆,仅依赖当前信息。
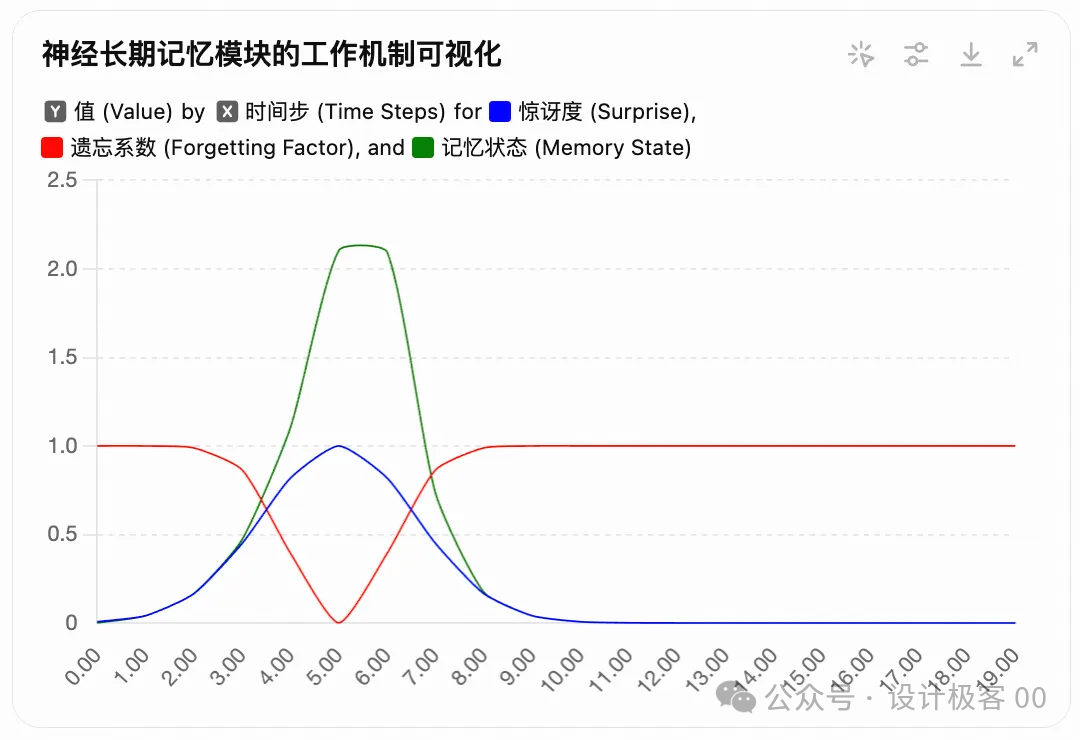
上图说明了神经长期记忆(LTM)的记忆更新机制,包括:
-
惊讶度(Surprise)(蓝色虚线)
- 当输入数据与过去信息存在较大差异时(如时间步 t=5 附近),惊讶度上升。
- 惊讶度越高,表示当前信息更重要,应该被存储到长期记忆中。
-
遗忘系数(Forgetting Factor)(红色点线)
- 记忆随时间可能会被遗忘,但当数据较为稳定时(如时间步 t>10),遗忘系数降低,使得旧记忆更易被保留。
- 记忆更新时,遗忘系数决定了旧记忆保留的比例,值越大意味着遗忘越多。
-
记忆状态(Memory State)(绿色实线)
- 结合惊讶度和遗忘系数,展示了记忆的累积状态。
- 在 t=5 附近,由于惊讶度较高,记忆状态快速上升。
- 在 t>10 之后,记忆状态趋于平稳,表明系统适应了新数据,且遗忘旧数据的影响。
记忆架构与检索
- 使用多层感知机( ≥2)作为记忆主体,增强非线性表达能力。实验表明,深层记忆(如 4 层)在长序列任务中表现更优。
- 优化目标:对记忆的损失函数,最小化键值对的预测误差,使记忆模块学习键值对的映射关系。
- 检索记忆时使用无权重更新的前向传播。
Titans 架构
架构组成
- 核心(Core):短期记忆,使用有限窗口大小的注意力处理数据,负责主要的数据处理流程。
- 长期记忆(Long-term Memory):神经长期记忆模块,负责存储过去的长时信息。
- 持久记忆(Persistent Memory):一组可学习但与数据无关的参数,编码任务相关知识。
变体设计
-
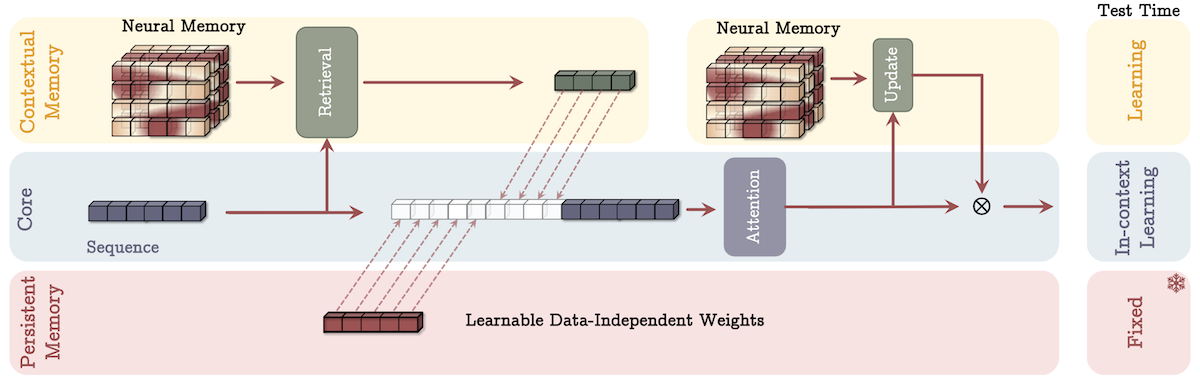
记忆作为上下文(Memory as a Context,MAC):将记忆视为当前信息的上下文,根据输入分段检索长期记忆信息,与持久记忆一起作为注意力模块的输入,注意力决定长期记忆的更新和信息存储,测试时各部分参数学习和固定情况不同。适用于语言建模和常识推理任务。
-
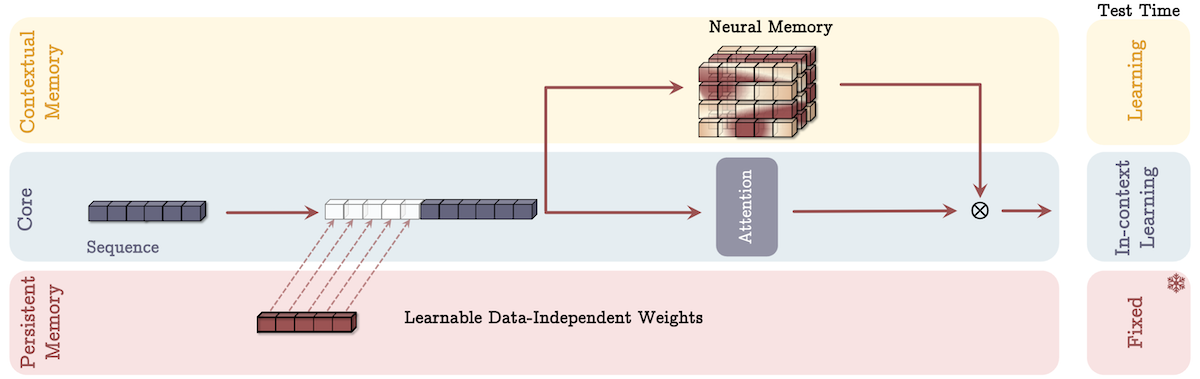
门控记忆(Gated Memory,MAG):一个分支直接用输入更新长期记忆,另一个分支使用滑动窗口注意力,通过非线性门控机制结合两者输出,滑动窗口注意力作为短期记忆,神经记忆模块作为衰减记忆。
- 适用场景:通过门控机制灵活调整对短期和长期信息的依赖程度,在需要快速响应和处理短期信息,同时又要兼顾长期信息积累的场景中表现出色。
-
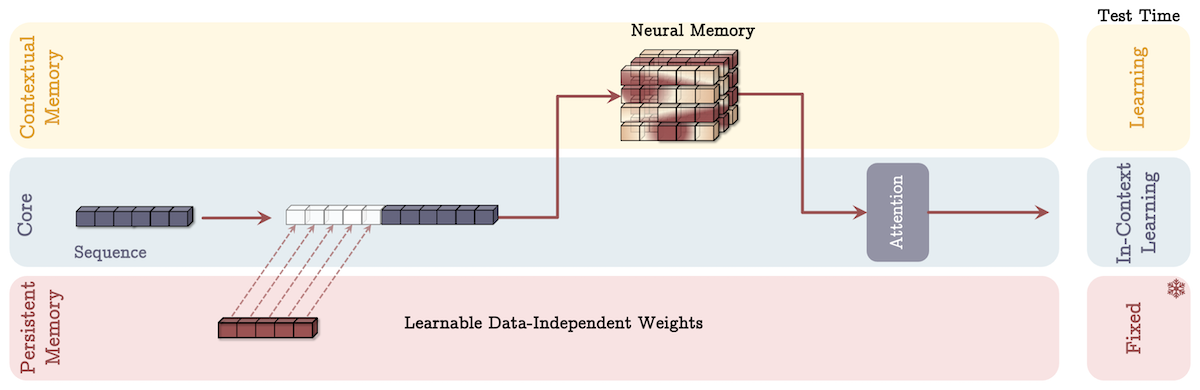
记忆作为层(Memory as a Layer,MAL):将神经记忆作为深度神经网络的一层,在注意力模块前压缩过去和当前上下文,但该设计可能限制模型利用注意力和神经记忆模块的互补处理能力。
- 适用场景:在资源受限的设备上进行简单的序列建模任务时,MAL 可以作为一种轻量化的解决方案,在不显著增加计算负担的情况下,为模型引入一定的记忆能力。
-
架构细节:各模块使用残差连接,在 q、k、v 值投影后加入 1D 深度可分离卷积层,在最终输出投影前使用归一化和线性层门控。
实验结果
- 语言建模与常识推理:在不同规模模型的实验中,神经记忆模块在非混合模型中表现最佳,Titans 的三个变体在混合模型中优于其他基线模型,MAC 在处理长依赖数据时性能更好。
- 针在干草堆任务:在单针检索的 S - NIAH 任务和更复杂的 BABILong 基准测试中,神经记忆模块和 Titans 变体均优于基线模型,MAC 表现突出,原因是能更好地处理记忆容量、具有深层非线性记忆和遗忘机制。
- 时间序列预测与 DNA 建模:在时间序列预测任务中,神经记忆模块替换 Simba 框架中的 Mamba 模块后,性能优于包括 Mamba、线性和 Transformer - based 等架构的基线模型。在 DNA 建模任务中,神经记忆模块在不同下游基因组学任务中与现有架构相比具有竞争力。
- 效率与消融研究:训练吞吐量方面,神经记忆模块比部分模型慢但具有更强大的记忆更新和存储机制,Titans(MAL)因使用高效内核比基线和记忆模块更快。消融研究表明 Titans 各组件对性能均有积极贡献,MAC 和 MAG 在不同任务中性能优于 MAL,体现了训练速度和表达能力的权衡。
这篇论文总体来说提出了一个创新的架构,在多个任务上展现出了优秀的性能,特别是在处理长序列数据方面。虽然存在一些实现上的挑战,但其提出的方法对于改进现有的神经网络模型具有重要的参考价值。